OPENVSWITCH ON SLACKWARE
2015-12-23

openvswitch
I want to create two VM on two separate hosts (one per host) that reside on the same network. I also
want the VMs to reside in a different network than the host's network. To do this with
openvswitch is really easy.
- Make sure openvswitch and tun/tap are compiled in kernel
- install openvswitch tools
- create bridge on each VMs
- create masquerading rules to share internet connection with VM network
Installing openvswitch
Openvswitch is already part of the kernel. It needs to be enabled when compiling the kernel. Then
the tools need to be installed. On slackware, it was just a matter of ./configure, make, make install.
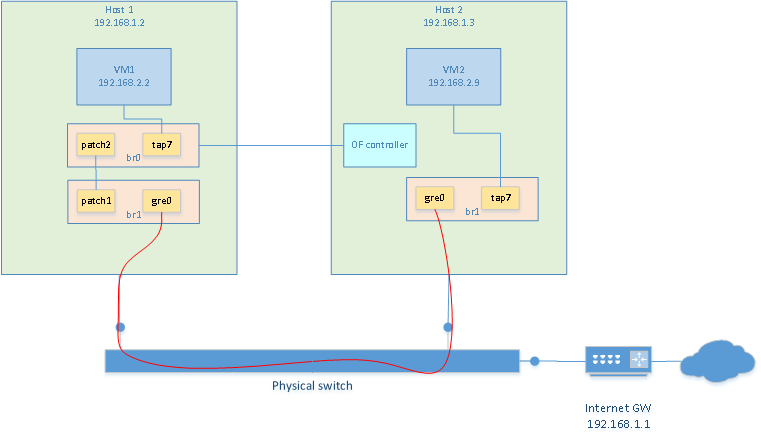
Creating a bridge with GRE tunnel
To have both VMs communicate with each other, we can build a virtual switch that spans
accross the two hosts. This is done with a bridge containing a GRE tunnel.
Creating a bridge on each VMs is done as follow. Unless noted otherwise, these commands
should be re-executed after every reboot
# create tun/tap adapters
/usr/sbin/tunctl -t tap7
# launch openvswitch server
ovsdb-server --detach --remote=punix:/usr/local/var/run/openvswitch/db.sock --remote=ptcp:6640
ovs-vsctl --no-wait init
ovs-vswitchd --pidfile --log-file --detach
# Creating the bridge. Adding tap interface and GRE tunnel in the bridge
# This is the exception: the following only needs to be done once as it will be persistant
/usr/local/bin/ovs-vsctl add-br br1
/usr/local/bin/ovs-vsctl add-port br1 tap7
/usr/local/bin/ovs-vsctl add-port br1 gre0 -- set interface gre0 type=gre options:remote_ip=**IP_ADDRESS_OF_OTHER_HOST**
# bring the bridge up
/sbin/ifconfig br1 0.0.0.0 promisc up
/sbin/ifconfig tap7 0.0.0.0 promisc up
Then repeat the same on the other host
Now, it is possible to start a VM on each host using their respective TAP7 interface. Each vm is
assigned an IP address in the same subnet but different than the one of the hosts. In my case
I used 192.168.2.2 and 192.168.2.9. Because a GRE interface is present in the bridges, both VM
can communicate with each other now.
Access to the internet
Since the VMs reside on subnet 192.168.2.0 but my internet gateway is at 192.168.1.1, there is no way
for my VMs to communicate with the outside world. So the first thing that needs to be done, is to
assign an ip address to the bridge of one of the host. This will be the gateway. So obviously, only
one is needed. I chose to put it on host2. So the "br1" on host1 still has no ip address assigned to it.
On host2 I did:
ifconfig br1 192.168.2.1/24 up
Then, masquerading needs to be done. This is not absolutely required. But if nat is not used, then
the gateway of the host's network must know about the VM network and have a route to redirect
traffic to the 192.168.2.1 gateway. In my case, I chose to use NAT. The following commands did
the trick:
# Enable forwarding. So that linux will see that
# traffic on br1 that wants to go out on a network known by another
# interface, eth0 in my case, will be forwarded on that interface.
echo 1 > /proc/sys/net/ipv4/ip_forward
# Create IP masquering rules. Assuming that eth0 is the host's interface that can
# communicate with the internet gateway (or is the gateway). Packets destined
# for external traffic will leave out eth0. So make a postrouting rule
# that will masquerade those outgoing packets. This will allow other networks
# to reach the VM network without knowing anything about it.
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Of course, the default route, within the VMs, should point to 192.168.2.1. At this point
VMs should be able to connect to this website
Additional notes
-
port of type "patch" can be used to "connect a patch cable" between 2 vswitches. This would
be used to connect two vswitches together as long as they reside on the same host. To connect
two vswitches that reside on different hosts, a port of type GRE would be needed.
-
To get additional information on what type of interface can be created (patch, internal, gre, etc.): http://openvswitch.org/ovs-vswitchd.conf.db.5.pdf
-
In the example above, the ovsdb-server was started with --remote=ptcp:6640. This means that it is possible
to control the vswitch from any other host using "ovs-vsctl --db=tcp:192.168.1.2:6640 ". This is great
when a virtual switch spans across several host because all host bridges can be controlled from one single point.
Openflow
The best description of OpenFlow and SDN I found was this:
OpenFlow is a protocol which lets you offload the control plane of all the switches to a central controller and lets a central software define the behavior of the network (also called Software Defined Networks). To me, that description was the one that opened the doors to SDN in a time where all of those terminologies was confusing to me.
Flows
Before going any further, let's first define what a flow is. An open flow switch makes
forwarding/routing decisions based on its flow tables. Each flow represent a "rule" that
must be matched and the action that must be taken if the rule does match. Flows are added
by a separate piece of software to the switch. The switch does not "build" its own flows.
These must be explicitely added to the switch by the switch administrator when first
configuring the switch or dynamically by an SDN controller. If using an SDN controller,
when a frame/packet/segment does not match any flows, it will be sent to the SDN
controller in order to find a flow that matches.
The flows contain a "match" part. It defines fields of frame/packet/segment must be
matched so that the flow applies. If the flow does apply, then the "action" part is used.
Matches can be specify that a flow must match a source MAC address, a destination TCP port,
or any other L2/3/4 fields. Combinations of fields can be matched and wildcards can be used.
The flows also contain an "action" part. Actions are very flexible. I won't detail
all the possible actions here. An action could be to drop the packet, forward the frame,
redirect to another flow table (internal to the switch) etc.
Using openflow with openvswitch
The man page for ovs-ofctl contains a section that details the flow syntax. Here is an example
on how to add a flow that would drop any TCP segment with destination port 80
ovs-ofctl add-flow br0 "table=0, tcp,tp_dst=80, actions=drop"
This one would rewrite any segment going towards TCP port 80 to go to tcp port 25. This is
basically port forwarding. Note that two flows need to be written. Once the server on port 25
sends a reply, it needs to be modified to use port 80 since the client is expecting to be
communicating on port 80.
ovs-ofctl add-flow br0 "table=0, tcp,tp_dst=80,nw_dst=192.168.2.2, actions=mod_tp_dst:25,normal"
ovs-ofctl add-flow br0 "table=0, tcp,tp_src=25,nw_src=192.168.2.2, actions=mod_tp_src:80,normal"
This will add flows to the bridge on the local host. This could be done when configuring the
switch initially. Obviously, more complex (and more useful) flows could be written, but this
is just to get a hang of it.
It could also be useful to have the switch's flow tables be populated dynamically by some other
"brain". Such a brain would be an "opendlow controller". The controller can reside on a separate
host.
I downloaded pox, an openflow controller, on one of my host. I am
running it on a different host than the one that is hosting the vswitch.
vswitch is running on 192.168.1.2 and pox is running on 192.168.1.3
git clone https://github.com/noxrepo/pox
cd pox
./pox.py forwarding.l2_learning
And then, on the vswitch host, I tell the bridge who the controller is
ovs-vsctl set-controller br0 tcp:192.168.1.3:6633
Using "forwarding.l2_learning" with pox creates a very basic flow that makes
the switch act like a normal layer2 switch. You could write other modules
for pox, but that is beyond the scope of this example. At least, now you know
how to have a remote controller generate the flows dynamically. You could download
another software to do it or even write your own.
By the way, using an openflow controller, we could drop the iptables usage from the above section and implement NAT using openflow only.
What this means
I wanted to learn what this was all about and I'm glad I did. I don't fully
understand how this can be very usefull though. I do see the power that this
brings to networking infrastructures. But for me, running a couple of computers
in my basement with a relatively simple setup, it is not that usefull. I can't
list a lot of uses-cases where this would change the world. I'm sure that one
day, I'm going to stumble across a problem and say "Hey! That would be super-easy
to do with openflow" and I'm gonna be glad I learned the basics of it. And now, 2017, I do fully understand the benefits of it because I work for a major SDN solution manufacturer :)
SHA256 ASSEMBLY IMPLEMENTATION
2015-12-17
Assembly implementation
For a moment now, I've been wanting to try the intel AVX instructions. So I decided to write an
SHA256 function in pure x86-64 assembly. That algorithm might not be the best thing
to parallelize though but it still was fun to do.
Update dec 16 2015: I have modified my code to use AVX2 instructions. I recently bought a Intel i5-6400 which supports a lot of new instructions I didn't have before. So I modified the algorithm to use bleeding-edge instructions.
Performances
The use of AVX instructions in this algorithm might not give better performances.
The only reason I did this was because I wanted to play with AVX. Using AVX2 probably helps a lot more since a lot of the AVX instructions are eliminated.
In fact, I'm not entirely convinced that using AVX will benefit a lot. One thing to consider here, is that for small hashes it could be slower. The thing is that when using AVX, you are using the xmm/ymm registers. During a context switch, the OS does not automatically save/restore the state of the AVX registers. Those are lazy-saved. Meaning that, without going too much into the details, the CPU will only save/restore the AVX registers if it detects that the current thread is using them (using a dirty flag and an exception). Such a save/restore is crazy expensive. So introducing the usage of AVX registers in a thread will cost a lot for the context switch, yielding less processing time for the thread.
So the thing to consider is: will the thread use the AVX instructions enough to overcome the cost of the context switch?
PROCESS CONTEXT ID AND THE TLB
2015-11-11
In an earlier post I said that the x86_64 architecture did not have a way
to tag TLB entries. Apparently, it is possible. I don't know how I missed it.
But there are caveats. I wrote another post about memory paging:
Memory Paging
What the TLB does
The TLB is a cache for page translation descriptors. It stores information
about virtual to physical memory mapping. When the CPU wants to access memory,
it looks for a translation in the TLB. If a translation is not cached in
the TLB, then this is considered a "TLB miss". The CPU then has to fetch
the page descriptor from RAM using the table pointer stored in register cr3.
Once the descriptor is loaded in the TLB, it stays there until the TLB gets
full. When the TLB is full, the CPU purges entries to to replace them with
newer ones. Access to the TLB is a lot faster than accesses to RAM. So
The TLB really is just a page descriptor cache.
Benefits of TLB tagging
On the x86 architecture, when loading the cr3 register with a new PML4 address,
the whole TLB gets invalidated automatically. This is because entries in the
TLB might not describe pages correctly according to the new tables loaded.
Entries in there are considered stale. Adress vX might point pX, but before
the PML4 change, it was pointing to pY. You don't want the CPU to use
those mappings.
Normally, you would change the mapping on a process change. Since the
page mapping is different for each process. But the TLB is quite large.
It could easily hold entries for 2 processes. So a TLB flush would
be expensive for no reason. That is why Process Context Identifiers (PCID)
were introduced.
First, you need to enable the PCID feature on the CPU in the cr4 register.
With PCID enabled, a load to cr3 will no longer invalidate the TLB
So this is dangerous if you do not maintain the PCID for each process at that point.
Now, everytime you load cr3, you must change the current PCID. Each Entry
added in the TLB will be tagged against the current PCID. This "tag" is
invisible to us, it is only used internally in the TLB (The whole TLB
is invisible to us anymway). So now, if two process access adrress vX
with two different physical mapping, those two addresses can reside
in the TLB without conflicting with each other. When doing a lookup in the TLB
the CPU will ignore any entries tagged against a PCID that is different
than the current one. So if virtual address vA exists in the TLB, and
is tagged with PCID-1, then process 2 tries to use address vA, the CPU will
generate a TLB-miss. Exactly what we want.
But then what about pages such as the one that contains the interrupt handler
code? Every thread will want such a page mapped and the mapping would
be identical. Using PCIDs would result in several TLB entries describing
the same mapping but for different PCID. Those entries pollute the TLB
(and waste precious cache space) since they all map to the same place.
Well this is exactly why there is a "g" bit, the Global flag, in each
page descriptors. The CPU will ignore the PCID for pages that are global,
It would be considered an incorrect usage of the paging system if a
page is global but has a differnt physical address on different threads.
So the global flag is to be used carefully. I use it for kernel code and MMIO.
Advantages at a certain cost
So PCIDs are a way to avoid flushing the TLB on each cr3 load,
which would become VERY expensive as the CPU would generate TLB-misses
at every context switch. Now, there are no more TLB flushes but the tagging
still guarantees integrity of page mapping accross threads. Can you see
how important that feature is and how big the befefits are? This will
considerably increase performances in your OS.
But there is one thing you must consider. When destroying a process and then,
possibly, recycling the processID for a new process, you must make sure
that there are no stale entries of that last process in the TLB. The INVPCID
instruction is just for that. It will allow you to invalidate all TLB
entries associated to a particular PCID. But then, if you are running in
a multi-CPU system, things get complicated. The INVPCID instruction will
only execute on the CPU executing it (obviously). But what if other CPUS
have stale entries in their TLB? You then need to do a "TLB shootdown".
In my OS, a TLB shootdown is done by sending an Inter-Processor Interrupt (IPI)
to all CPUs. The IPI tells them to invalidate their TLB with the PCID that
was shared as part of the IPI. As you can guess, this can be very
costly. Sending an IPI is very expensive as all CPUs will acquire a lock,
disabled their interrupts plus all the needed processing.
But it would only happen everytime a new process gets created.
How to use it
First, enable the PCID feature. This is simply done by setting bit 17 in CR4.
Then, everytime you load CR3, the lower 12bits are used as the PCID.
So you need to guarantee a unique 12bit ID for every process. But that
can be a problem. 12bits only allows 4096 processes. If you plan on supporting
more than 4096 process simultaneously, then you will need to come up with some
dynamic PCID scheme.
Unfortunately, my CPU does not support INVPCID. It does support PCID though. It make no sense, in my head, that the CPU would support PCID but not INVPID. So I had to work around it. I found the solution
by starting a thread at forum.osdev.org.
By setting bit 63 of cr3, the CPU will delete all TLB entries associated with the loaded PCID. So I came up with the following solution
////////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////////
// emulate_invpcid(rdx=PCID)
// will invalidate all TLB entries associated with PCID specified in RDI
// This emulation uses bit63 of cr3 to do the invalidation.
// It loads a temporary address
////////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////////
emulate_invpcid:
push %rax
and $0xFFF,%rdi
or $PML4TABLE,%rdi
btsq $63,%rdi
mov %cr3,%rax
// We need to mask interrupts because getting preempted
// while using the temporary page table address
// things would go bad.
pushfq
cli
mov %rdi,%cr3
mov %rax,%cr3
popfq
pop %rax
ret
THREAD MANAGEMENT IN MY HOBBY OS
2015-10-26
I thought I'd write a little more about my home-grown x86-64 OS. This is about my threading mechanism.
The Task list
The global task list contains a list of 16bytes entries that contains the adress of the PML4 base
for the task and the value of the Ring0 RSP. Since task switches always occur during Ring0, only
the RSP0 needs to be saved (RSP3 will have been pushed on stack during privilege change).
Upons switching task, the scheduler will restore cr3 and rsp from the list.
Task State Segment
In 64bit long mode, the TSS doesn't have as much significance than in protected mode when hardware
context switching was available. The TSS is only used to store the RSP0 value. When a privilege
change is performed, from Ring3 to Ring0, the CPU will load the TSS.RSP0 value in RSP and the old
RSP3 value will have been pushed on the Ring0 stack. So the IRET instruction will pop out the Ring3
RSP value (hence why it is not needed in the TSS). The only time that the CPU will look into the TSS
is during a privilege switch from Ring3 to Ring0.
Only one TSS is needed in the system since the value it contains is a virtual address. Every task
will use the same address for RSP3 and RSP0 but it will be mapped differently.
So the TSS is only used to tell the process which address to use for the stack when going from Ring3
to Ring0. Since that address is the same virtual address for every task, only 1 TSS needs to be created.
There is no point in showing the TSS here since only one value is used. It's basically a 0x67 bytes long table
with a 64bit entry at byte index 4 that represents the RSP0 value. the rest of the table can be filled with zeros
Kernel and user tasks
Kernel tasks have the following properties:
- Run in ring0.
- Their Code Segment Selector is the same as the kernel.
- Each kernel task has its own stack.
- Code is located in kernel memory which is the identity-mapped portion of virtual memory.
- The RSP value that is set in the Ring0 stack (for iret) upon task creation is the ring0 stack pointer.
User tasks have the following properties:
- Run in ring3
- Their Code Segment Selector is the same for all user thread.
- Their Code Segment Selector has DPL=3
- Each user task has 2 stacks: one for Ring0 and one for Ring3
- Code is relocated at load time and appears to be running at virtual address 0x08000000
- The RSP value that is set in the ring0 stack (for iret) upon task creation is the ring3 base stack pointer.
Interupts
When an interrupt occurs, the Trap or Interrupt Gate contains a DPL field and target Selector field. The DPL
will always be set to 3 so that any privilege levels (Ring0-Ring3) can access the interrupt handler. The target
selector is for a Code Segment Descriptor (inthe GDT) with a DPL value of 0. This will effectively run the
handler in Ring0.
Interrupt or task switch during user task
If the interrupt occured during a user task, the task may have been in Ring3 or in Ring0 if in the middle of a
system call. If a privilege change occurs, the value of RSP will be set to the value in the TSS for RSP0. That
value is the same for all tasks but mapped differently to physical memory. The ring3 stack will be left untouched.
If there is no privilege change, then the same stack will be used. The scheduler algorithm doesn't need to change
since the Ring3 stack's RSP has been pushed sometime before when entering Ring0 (ie: when calling a system
function)
Interrupt or task switch during kernel task
If the interrupt occured during a kernel task then nothing special happens. The same stack is being used and same
protection level is applied. Although it would be possible to use the new ITS mechanism to use another stack
during interrupt handling. This would be usefull, for example, when a stack overflow occurs in a kernel thread
and the #PF exception is raised. If there is not stack switch, then the return address can't be pushed on the stack
since the stack if faulty (hence the #PF). So using another stack for interrupts would be a wise choice. But
I'm not implementing this for now.
Task switch
A task switch will always be initiated by the timer iterrupt. The scheduler runs in Ring0 so the
Ring0 stack is used. If the interrupted task was in Ring3, we don't need to worry about its stack
since RSP has been pushed on the Ring0 stack.
The current CPU context will be saved on the Ring0 stack. Therefore, the scheduler will always save the RSP
value in the tasklist's rsp0 entry since it occurs in ring0 code. Upon resuming the task, RSP will be reloaded from
the rsp0 entry, context will be restored and the iret instruction will pop the ring3 RSP to resume execution.
In a multi-cpu system, it would be possible to have less threads running than the number of CPUs. In that case, upon
task-switching, a CPU would just continue to run its current thread, giving 100% of its time to that thread. But for
other CPUs that don't have any task to execute, they should get parked. Once a CPU's thread is terminated, if
there is no other threads to run for him, then it will parked. Normally the CPU would load the context
of the next task but instead it will simply jump to a park function. Since the scheduler is invoked
through an interrupt, we eventually need to "iret". But in the case of parking, we will just "jmp" to a
function and spin indefinitely. The iret instruction would restore flags and pop out the stack a jump to a return
address but in this case we don't want to do any of that. Since there are no flags to restore, no return function
and no stack to clean. The park function does the following:
- load kernel PML4 base address in cr3 to restore identity paging
- load RSP with a stack unique for the current CPU
- acknowledge interrupt (APIC or PIC)
- restore interrupt-enable flag (cleared when entering handler)
- spin-wait with "hlt" instruction.
parkCPU:
// Set back the kernel page tables,
mov $PML4TABLE,%rax
mov %rax,%cr3
// set back the cpu's stack. This could be
// optimized but kept the way it is for clarity purposes.
// We're parking the CPU... it's not like we need the performance here
mov APIC_BASE+0x20,%eax
shr $24,%eax
mov %rax,%rsp
shl $8,%rsp
add $AP_STACKS,%rsp
// re-enable interrupts and set some registers for debug and wait
mov $0x11111111,%rax
mov $0x22222222,%rax
mov $0x33333333,%rax
call ackAPIC
sti
1: hlt
jmp 1b
Since interrupts are re-enabled and APIC has been ack'd, we will continue to be interrupted by the timer
and we are ready to take on a new task at any time. It would be wise to warn the parked CPU about
newly created tasks (with IPIs) so we don't need to wait until the timer to kick in. But that's for
another day.
Creating a new task
When a new task is created, memory is allocated for its stack and code. An initial context is setup
in the newly created stack. All registers are initialized to 0. Since the task will be scheduled by an interrupt handler,
it needs to have more data initilased in the stack for proper "iret" execution. Of course, the RSP value saved
in the task list will be the bottom of that context in the task's stack.
The initial stack looks as follow:
| Stack top |
| 152 |
SS |
0 for kernel thread / Ring3 selector for user thread |
| 144 |
RSP |
Ring0 stack top or Ring3 stack top |
| 136
| RFLAGS |
0x200202 |
| 128 |
CS |
Ring0 Code selector or Ring3 Code selector |
| 120 |
RIP |
entry point for Kernel thread / 0x080000000 for User thread |
| 112 |
RAX |
0 |
| 104 |
RDI |
0 |
| 96 |
RBX |
0 |
| 88 |
RCX |
0 |
| 80 |
RDX |
Parameter to pass to thread on load |
| 72 |
RSI |
0 |
| 64 |
RBP |
0 |
| 56 |
R8 |
0 |
| 48 |
R9 |
0 |
| 40 |
R10 |
0 |
| 32 |
R11 |
0 |
| 24 |
R12 |
0 |
| 16 |
R13 |
0 |
| 8 |
R14 |
0 |
| 0 |
R15 |
0 |
| Stack bottom |
Scheduling algorithm
My scheduling algorithm is nothing fancy. Just the good old round-robin way. But on multi-processor, it is probably the worse
thing you could do. Here is an example task list (Note that I should also use a linked list instead of a fixed size table)
| Task1 |
| Task2 |
| Task3 |
| Task4 |
| Task5 |
As this table show, each task except Task5 are running on one of the 4 CPUS. At the next schedule(), the task list will look like this:
| Task1 |
| Task2 |
| Task3 |
| Task4 |
| Task5 |
The problem here is that Task 1,2 and 3 are still running. So doing a context switch imposed a large overhead for no reason.
But the fact that they are still running is good, but they are not running on the same CPU anymore. So they will never
fully benefit from the CPU cache since memory will need to be fetched all over again because that CPU had no idea about
the code and data being used by the task. A better algorithm would detect that the task should continue to run on the same CPU.
I need to take the time to think about it.
Ring 3 tasks
To make a task run in ring3, it needs the following
- A "non-conforming" code segment descriptor with DPL=3.
| 63 |
Irrelevant |
1 | 0 | 0 | 0 | Irrelevant |
48 |
| 47 |
P:1 | DPL:3 | 1 | 1 | C:0 | R:1 | A:0 |
Irrelevant |
32 |
| 31 |
Irrelevant |
16 |
| 15 |
Irrelevant |
0 |
- cs must be loaded with RPL=3
| 15 |
GDTIndex15:3 |
TI:0 | RPL=3 |
0 |
- A writable data segment with DPL=3. This is for the stack.
| 63 |
Irrelevant |
1 | 0 | 0 | 0 | Irrelevant |
48 |
| 47 |
P:1 | DPL:3 | 1 | 0 | E:0 | R:1 | A:0 |
Irrelevant |
32 |
| 31 |
Irrelevant |
16 |
| 15 |
Irrelevant |
0 |
- ss must be loaded with RPL=3
| 15 |
GDTIndex15:3 |
TI:0 | RPL=3 |
0 |
- The task register must be loaded with a valid tss selector. The TSS should be initialzed with a valid RSP0 value
for when the code switches to Ring0 (interrupts). TSS Descriptor:
| 63 |
base31:24 |
1 | 0 | 0 | 0 | 0 |
48 |
| 47 |
P:1 | DPL:3 | 0 | 1 | 0 | 0 | 1 |
base23:16 |
32 |
| 31 |
base15:0 |
16 |
| 15 |
0x67 |
0 |
Please refer to Intel 64 and IA-32 Architectures Software Developer's Manual Volume 3 for more information
These values would be on the stack prior to invoking "iret" from the scheduler. The scheduler runs in
ring0, hence why the RPL value in selectors is important
Memory layout
The kernel's page tables is as follow:
- The first 128mb is identity mapped using 2mb pages (first 64 page directory entries).
- The rest of the available memory is identiy mapped with 4k pages.
- The whole memory is again identity mapped, using 2mb pages, at 0x4000000000.

The kernel's 4k pages is only used to track free pages to be distributed to requesting threads.
Each 4k page entry has its 3 AVL bits cleared. This is how the kernel keeps track of available memory.
A page with non-zero AVL is in use.
So when a process needs to create a new page, it does the following:
- look through the kernel 4k pages structure for a free page. Mark is as not-free
- look though the process 4k pages structure for a free page. Mark is as not-free
- take the physical address of the kernel page (easy since it is identity mapped)
and store it in the process page entry. The process's page now maps to the proper physical page.
The AVL bits are set as follow:
- 0b000: physical memory pointed to by this page is free to use
- 0b001: physical memory pointed to by this page is also mapped somewhere else and is a stack page for a thread
- 0b010: physical memory pointed to by this page is used by the kernel
- 0b011: physical memory pointed to by this page is used as heap for a thread or the kernel
Creating a process
When creating a new process, the process code will start at 0x8000000. So the kernel will reserve a physical
page (as per the process in step 1 above). The physical address of that page will be used in the process's page
entry for address 0x8000000. This should correspond to Page Directory entry #64. Since the first 64 entries
are 2mb pages and the rest are pointers to page tables, then this virtual address maps to a 4k page.
So all processes will see their entrypoint at 0x08000000 but they will obviously be mapped to different
physical pages. This allows to to compile position dependant code and run it in the OS.
Whole memory identity mapping
Each process have their own virtual address mapping.
If a process calls a system function that needs to manipulate physical
memory this causes a problem. For example, if a process wants to allocate memory, it needs to access it own page tables.
but the pages reside above kernel memory so it is not mapped into process virtual addressing space. The same can happen
when trying to create a process: The system call will reserve a virtual address in its page tables,
which is identity mapped, but then it will attempt to fill in some data in the physical page,
that physical page resides above the kernel memory, so it is not mapped in the process. for example:
- Kernel memory ends at 0x08000000. Kernel page tables are 0x00020000.
- The kernel page tables is just a list of identity mapped pages above kernel memory
with the AVL field indicating if the page is available.
- The first entry maps to physical location 0x08000000. So when searching for a free page, the kernel will
find, for example, an entry at 0x00020B00 with the AVL bits set the "free".
- This entry maps to 0x08000000+(4096*(B00/16)) = 0x080B0000.
- The process would like that physical address to be mapped to 0x08001000 and fill it with zeros.
Two problem arises:
- The process cannot modify its page table to write an entry for 0x08001000 since
its page tables are not mapped.
- It cannot fill the page with zeros prior to map it since the page is not mapped and it
cannot access 0x080B0000 directly because this is a physical address and it would be interpreted
as a virtual address by the CPU.
The solution is to keep an indentity mapping of the whole memory at some other address. Lucky for us, with 64bit
addressing we have a very large address range. So identiy mapping will start at 0x4000000000 (256th gig).
That address will map to physical address 0x00000000. So by getting the PLM4 address from cr3 and
adding 0x4000000000 (or simply setting bit38), the process can now access its page tables.
Dynamic stack growth
A user thread is created with a 20mb stack but only the 4 pages are allocated (commited to physical memory).
If the thread attempts an access below that 16k, a Page Fault exception (#PF) will occur since the page will
not be mapped (unless the access went as far down as the heap,in which case corruption would happen). The #PF
handler will then allocate a page for that address
My implementation is rather simple. It allocates
physical pages upon page faults and that's it. The only protection it does is
to check if the address is in the page guard. The page guard is a non-present
page between the heap top and stack bottom. If a stack operation would
fall in that page, then the OS detects this as a stack overflow. But there is
nothing that protects a task to do something like "movq $1, -0x1000000(%rsp)".
This could fall below the page guard and corrupt the heap. Same thing for the heap.
Nothing prevents a task from writting to an address that falls in the stack.
So the the page guard is a best-effort method.
It would be nice if the Exception error code would tell us if this operation was using rbp or rsp,
or any implied usage of the ss segment segment selector.
for example, all these operations should be recognized as stack growth demand:
- push %rax
- mov %rax,(%rsp)
- mov %rax,-5000(%rbp)
- mov %rax,-5000(%rbp)
- And to some extent: lea -10000(%rsp),%rax; mov %rbx,(%rax)
To make sure that we touch the page guard, we need to do Stack Probing:
// This would be dangerous
void test1()
{
char a[0x2000];
a[0]=1;
}
// This would be safe.
void test1()
{
char a[0x2000];
// the fact that we access a page that is no further than 0x1000 from
// the bottom of the stack will make the #PF correctly create the page
// Doing this is called Stack Probing
a[0x1001] = a[0x1001];
a[0]=1;
}
It's impossible to detect all those conditions. So unfortunately, it is not possible to detect if the
demand is for a legitimate stack growth, stack overflow or heap overflow. So we just blindly allocate the page
and give it to the requesting task.
After trying to find an alternate solution, I found out that apparently Windows and linux are facing the same dillema.
Apparently, my algorithm is good. When compiling a C application
under those OS, the compiler will detect if the program tries to allocate more than one page on the stack and
will generate "stack probing" code. So Stack Probably is a well-known technique to work around that limitation.
But if you write a ASM application under linux or windows, then you need to take care of that.
Another possible way I will eventually explore is to set the stack memory at virtual location 0x1000000000000.
By looking at bit 47of the offending address, I would get a strong hint about this being a stack operation.
This means the OS couldn't support systems with more than 256 terabytes of RAM.... It also has other downsides.